About naampy¶
The ability to programmatically and reliably infer the social attributes of a person from their name can be useful for a broad set of tasks, from estimating bias in coverage of women in the media to estimating bias in lending against certain social groups. But unlike the American Census Bureau, which produces a list of last names and first names, which can (and are) used to infer the gender, race, ethnicity, etc., from names, the Indian government produces no such commensurate datasets. Hence inferring the relationship between gender, ethnicity, language group, etc., and names has generally been done with small datasets constructed in an ad-hoc manner.
We fill this yawning gap. Using data from the Indian Electoral Rolls (parsed data here), we estimate the proportion female, male, and [third sex]{.title-ref} (see here) for a particular [first name, year, and state.]{.title-ref}
Please also check out pranaam that uses land record data from Bihar to infer religion based on the name. The package uses indicate to transliterate Hindi to English.
Data Sources¶
Electoral Roll Data¶
The package capitalizes on information from parsed electoral rolls from 31 states and union territories of India:
North India: Delhi, Haryana, Himachal Pradesh, Jammu & Kashmir, Punjab, Uttarakhand
South India: Andhra Pradesh, Karnataka, Kerala, Tamil Nadu
East India: Bihar, Jharkhand, Odisha, West Bengal
West India: Goa, Gujarat, Maharashtra, Rajasthan
Central India: Chhattisgarh, Madhya Pradesh, Uttar Pradesh
Northeast India: Arunachal Pradesh, Assam, Manipur, Meghalaya, Mizoram, Nagaland, Sikkim, Tripura
Union Territories: Andaman & Nicobar, Chandigarh, Dadra & Nagar Haveli, Daman & Diu, Lakshadweep, Puducherry
Data Processing Methodology¶
Name Parsing: Names are split into first and last names
Aggregation: Data is aggregated per state and first name
Statistics Calculated:
prop_male: Proportion of males with the nameprop_female: Proportion of females with the nameprop_third_gender: Proportion of third gender individualsn_female: Count of femalesn_male: Count of malesn_third_gender: Count of third gender individuals
Temporal Analysis: Birth years are calculated based on age (data collected in 2017)
Transliteration: Native language rolls are transliterated to English using indicate
Machine Learning Model¶
When a name doesn’t exist in the electoral roll database, naampy uses a machine learning model that learns the relationship between character sequences in first names and gender.
Model Architecture¶
Type: Character-level neural network
Problem Formulation: Regression (predicts female proportion)
Training Data: Indian electoral roll names
Classification: Names with predicted proportion < 0.5 are classified as male, otherwise female
Model Performance¶
On test data:
MSE (Mean Squared Error): 0.05
RMSE (Root Mean Squared Error): 0.22
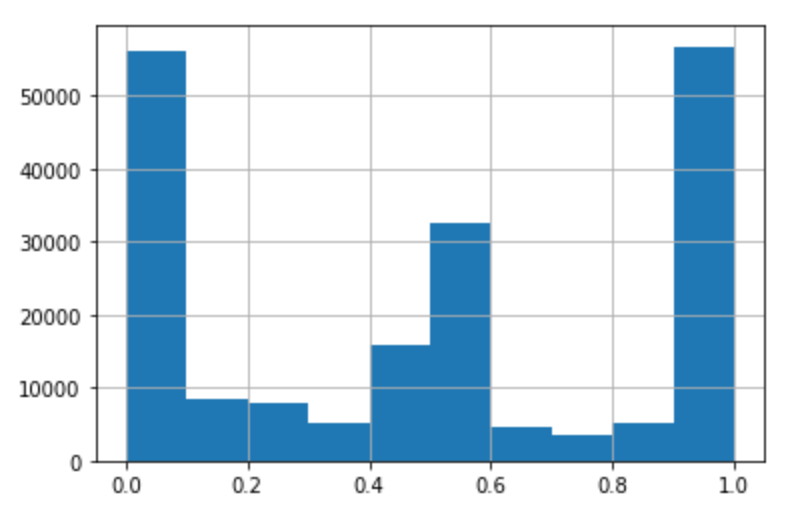
The model handles the fact that some names are shared between men and women, as shown in the distribution of female proportions:
Inference Results¶
The model shows strong performance across different name types:

Important Considerations¶
Data Limitations¶
Registration Bias: Voting registration lists may underrepresent certain groups (poor people, minorities)
Adult Census: Electoral rolls only include adult citizens, potentially missing gender biases that prevent individuals from reaching adulthood
Name Parsing: Indian names are complex with various formats and conventions
Transliteration Quality: For non-English/Hindi electoral rolls, transliteration quality may vary
Ethical Considerations¶
Privacy: All data is aggregated; no individual-level information is exposed
Use Cases: Should be used thoughtfully and ethically
Accuracy: No name-based method is 100% accurate
Cultural Sensitivity: Respect the diversity of Indian naming conventions
Citation¶
If you use naampy in your research, please cite:
@software{naampy,
author = {Laohaprapanon, Suriyan and Sood, Gaurav and Chintalapati, Rajashekar},
title = {naampy: Infer Sociodemographic Characteristics from Indian Names},
url = {https://github.com/appeler/naampy},
year = {2023}
}
License¶
naampy is released under the MIT License. See the LICENSE file for details.
Contributing¶
Contributions are welcome! Please feel free to submit a Pull Request. For major changes, please open an issue first to discuss what you would like to change.
Support¶
Issues: GitHub Issues
Documentation: This documentation
Interactive Demo: Streamlit App